
こんにちは、検索チームのよこやまです。最近はもっぱらハイラルにいます。世界を救うことを放棄して行う探索と工作はとても楽しいですね。
検索チームでは複数のプロダクトにわたり検索機能を管理しています。その中で、ある検索エンドポイントのみレスポンス速度が常に数秒かかっており、サービス体験に影響が出ていました。
今回はそのエンドポイントのレスポンス速度改善に向けて行った取り組みについてご紹介させていただきます。
実施した対応
まず結果として、レスポンス速度改善のためにした対応は下記 2 点です。
copy_toによる検索対象フィールドの集約- 長めの
refresh_intervalを設定
これらはどちらも Elasticsearch の公式ベストプラクティスに基づいたもので、特別新しい対策ではありません。
今回はその対応に至るまでに行った調査を主軸にご紹介します。
調査手順・詳細
1. 遅いエンドポイントの現状確認
まずは「遅い」と言っているエンドポイントのレスポンス速度が、実際にはどれぐらい遅いのか明確にします。
今回はアプリケーションログに残っている過去 1 ヶ月のレスポンスにかかった時間を集計し、平均・50% tile・90% tile・99% tile を出して改善のベースラインとしました。
当時の一部期間の計測値が以下になります。

平均値でも 3 秒近くになっており、改善が必要であることを再認識しました。
2. Elasticsearch公式ドキュメントの Tune for search speed を確認
Elasticsearch のドキュメントには Tune for search speed という検査速度改善のためのベストプラクティスが記載されているページがあります。今回は調査の前にこのページを改めて確認し、行えそうな対応の把握に務めました。
また、今回は別の文脈で Tune for indexing speed というインデキシング速度改善に関するページも確認していたのが功を奏しました。インデキシング速度改善が負荷の軽減となり、結果として検索速度の向上に繋がりました。
3. 仮説列挙
レスポンス速度が遅い要因を可能な限り列挙しました。
今回は要因の目処がついていなかったため、計測中に方向性を見失わないように、事前に考えうる要因を列挙し、「自分が今何を計測して、何のためにそれを行っているのか」を常に確認しながら進めました。
「極端に大きいフィールドを返しているのでは?」「tokenizer が要因なのでは?」「Elasticsearch が原因ではないのでは?」など、まずは粒度を考えず列挙してから整理し、荒い粒度の仮説は更に掘り下げを行いました。
これらの仮説を後の計測で確認していきました。その過程で新たな洞察を得ることも多く、その都度新たな仮説を追加し検証を進めました。
4. 計測・対応の効果確認
仮説の列挙と整理が終わったところで、計測と考えうる対応の効果の確認に取り掛かりました。
4.1 アプリケーションコード上からの計測
現時点で遅いことが確認できているのは検索機能エンドポイントのレスポンス速度であるため、上段のアプリケーションレイヤーから計測していきました。
まずは、Elasticsearch へのリクエストが、検索機能自体のレスポンス速度の主要因であることを確定させます。
今回はアプリケーションログ上に下記のような Elasticsearch へのリクエストログが残っていたため、これらを集計することにより Elasticsearch が遅さの主要因であることを明らかにしました。
POST https://******.cloud.es.io:443/my_index/_search [status:200 duration:0.05s]
また、今回は使用しませんでしたが、過去の似たような取り組みでは Python のプロファイラを利用しました。
過去の取り組みでは、Elasticsearch が遅さの要因ではなく、Elasticsearch からレスポンスを得た後の RDB 参照が要因でした。
下記のようなコードを差し込むと、それぞれの関数ごとにどれぐらい時間がかかっているか計測できるので非常に有用です。
import cProfile, pstats, io from pstats import SortKey pr = cProfile.Profile() pr.enable() # ... do something ... pr.disable() s = io.StringIO() sortby = SortKey.CUMULATIVE ps = pstats.Stats(pr, stream=s).sort_stats(sortby) ps.print_stats() print(s.getvalue())
4.2 現状のクエリ/mapping/データの確認
現状のクエリと mapping、インデックスされているデータを確認しました。 このときに前述の仮説と一致するものや、公式ベストプラクティスと反している内容を記録しておき、追々の計測でそこを修正した場合にどれぐらい速度が改善されるか確認しました。
4.3 Elasticsearchのプロファイラを使用した単発クエリの計測
ElasticsearchのProfile API を利用して単発のクエリで遅いリクエストが再現できないか確認しました。
表示にはKibanaのSearch Profilerを利用すると見やすいのでオススメです。
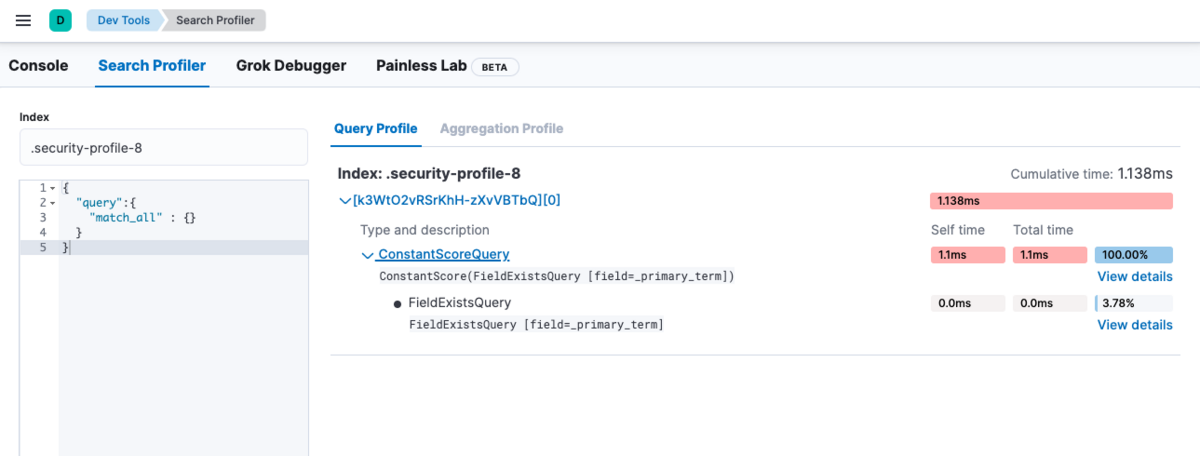
一方で、Kibana の Search Profiler にある Query Profile では、 Profile 結果にある Fetch Phase の情報が載りません。 Query Profile では Profile 結果の JSON をそのまま入れても可視化してくれるため、Profile 結果は Kibana の Console などで直接取得し、Query 部分を見るために Query Profile を利用するのが良いでしょう。
加えて、Elasticsearch の Profile API では確認できない項目があります。 一部例を挙げると、検索リクエストがキューにとどまっている時間は Profile 結果に載りません。詳細は公式ドキュメントを参照してください。
遅いリクエストが再現できた場合は、上記の仮説に基づいてクエリや mapping の変更を試し、速度に改善が見られないか確認します。 今回は遅いリクエストを確実に再現できなかったため、ページキャッシュなどの単発リクエストでは再現できない他の影響があると判断し、次項の Rally の使用に進みました。
4.4 Rallyを使用した複数リクエストの計測
Profiler によって遅い単発のリクエストが再現できなかったため、Rally を利用して、「インデックス作成→ドキュメント登録→検索リクエスト n 回実行」のシナリオを行い、その結果を集計することで単発リクエストに依存しない計測をしました。
Rally の使用方法についてはこちらの過去の記事をご参照ください。
過去記事と同様に既存のインデックスを利用してカスタムトラックを作成しました。 注意点として、カスタムトラックを使用する場合、指定したインデックスのデータをそのまま利用します。そのため、対象インデックスにセンシティブなデータが入っている場合、取り扱いに注意が必要です。
計測時に発行するクエリは、本番環境のクエリログを利用しました。 今回はゼロヒットクエリを除くことはせず、クエリ文字列の長い順にソートして間引きしました。
今回 Rally を利用する上での苦労と失敗は下記 2 点です。
計測結果が安定しなかった
今回の計測は独立した環境を用意し実施していましたが、同一のシナリオ・インデックス設定・データセット・クエリ集合を利用しても計測結果にブレが生じ、評価が非常に難しいものになりました。 そのため、計測結果を安定させるため下記に取り組みました。
- 検索試行回数を増加
- 検索試行前の warmup の追加
- 発行するクエリの種類の削減
- クエリ発行順序の固定*1
インデキシング負荷がかかっている状態の検索レスポンスを計測しなかった
今回の試験シナリオ(Rally の track.json)は「インデックス作成→ドキュメント登録→検索リクエスト n 回実行」という非常にシンプルなものでした。
このシナリオを採用した理由として、該当の検索機能はリクエスト数やインデキシング頻度が非常に多いものではなく、負荷による影響は少ないと判断したためです。
そのため Rally の利用目的は負荷試験の文脈よりも、複数回検索リクエストを試行した場合のレスポンス速度の統計取得に重きを置いていました。
しかし結果として、Rally による計測ではない調査・試行*2において refresh_interval の延長が有効であることがわかり、この判断は誤りだったことがわかりました。
parallelを利用し、インデキシングと検索の並列実行をシナリオに含めるべきでした。
5. 対応・結果
これらの調査から、サービス要件を満たしつつ検索速度の改善が見込める対応として「copy_to による検索対象フィールドの集約」が候補に上がりました。 加えて、別の文脈で効果があると判明した refresh_interval の延長も行ったところ、平均が 500ms 台、90% tile も 700ms 台と大幅に改善しました。

最後に
結果としてレスポンス速度の改善は達成しましたが、調査・計測はとても上手く行ったとは言えません。 思い込みからいくつかの可能性を事前に排除してしまい、Profile/Rally の計測で明らかにしきれなかった要因がありました。
しかし、今回の取り組みは自分自身にとっても非常に有意義なものでした。この経験を元に今後もビザスクの検索の改善を進めていきたいと思います。