こんにちは。SREチームの西川です。
SLOの運用開始から1年ほど経過した段階で、SREチームでSLO運用の振り返りを行いました。
今回は、SLO運用の振り返りの内容やそれを踏まえてSREチームとしてどのようなことを考えているかについてまとめてみます。
SLOの策定・導入までの進め方やそこでの気づきについては、下記の記事にまとめています。
どうして振り返りを行うのか?
ビザスクでは、去年の夏頃からSLOを設定して、運用を行ってきました。
運用の中では、SREチーム内でSLOを毎週確認して、変動があった場合はエラー数やレイテンシーの詳細情報を確認して開発チームに共有していました。
この段階では、SLOを踏まえたサービス改善のイテレーションを回すことにチームとして集中していた段階でした。
振り返って見ると、SLOは最低限に絞った状態で運用を回していたので、下記のようなメリットがあったと感じています。
- SLOは最低限に絞ったことで、SREチームとしてSLOの運用を十分回せる状態が継続できた
- チームとしてSLOの運用を継続する中で、SLOそのものや運用自体に対する改善点に目を向けることができた
Googleが提供するSLO策定・運用のプラクティスを見ても、SLO導入の最初の動きとしては適切な状態にあったと思います。
SLO は簡潔かつ明確なものにしておきましょう。SLO では、本当に気になる部分を曖昧にするのではなく、重要でない操作までカバーしないようにするほうがよいのです。規模の小さい SLO で経験を積んでください。まずはリリースして繰り返すのです。
優れた SLO を策定するには : CRE が現場で学んだこと (https://cloud.google.com/blog/ja/products/gcp/building-good-slos-cre-life-lessons)
一方で、先述の通り、SLOを踏まえたサービス改善に集中していたこともあり、新規開発や機能改修などを踏まえたSLO自体の見直しなどには着手できていない状況でした。
そこで、サービス改善がある程度進んだ段階で、チームとしてSLIの検討やSLOの見直しについて考え始めました。
SLO振り返りについて
SLOの振り返りは下記のような流れで実施しました。
振り返りの際には、SLOの利用目的などが当初の内容からズレていないか確認するために、SLO策定時に作成したドキュメントも利用しました。
- SLOの利用目的の再確認
- SLO運用全般に関する振り返り
- SLOに関する課題整理
- 課題を踏まえたネクストアクションの確認
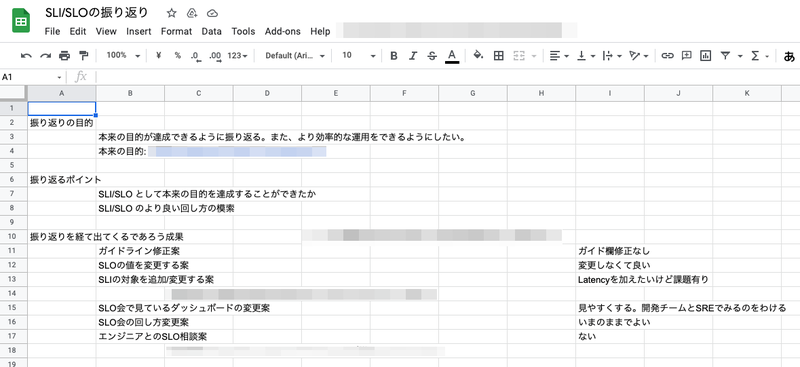
振り返りの中では特に、「SLO運用全般に関する振り返り」に時間を割いて、ディスカッションを行いました。
振り返りにあたって事前に、SLI・SLOの設定値から毎週実施しているSLO関連の確認事項に至るまで全般的な振り返り項目を列挙したスプレッドシートを用意しました。
それに対して、各メンバーが今までの運用を踏まえた課題・問題点・できている部分についてブレストの要領で記載していきました。

できている点も含めてディスカッションに臨んだことで、何がどこまでできているかの認識を合わせて、課題を踏まえたネクストアクションに対する線引きが適切にできたように思います。
振り返りの中では下記のような課題が挙がっていました。
- Request LatencyをSLI/SLOとして採用できていない
- SLO用のDatadog Dashboardでの確認項目が増えるにつれて、Dashboard自体が煩雑になっていた
- サービス開発チームにSLOを主体的に見てもらうための働きかけが不足していた
振り返りを踏まえた課題
一連の振り返りとそこで挙がった課題項目を踏まえて、現在SREチームでは下記の課題に対する対応に当たっています。
SLOの追加 (Request Latency)
先述の通り、SLI/SLOの導入時には、一度に複数のSLOを運用開始することへの懸念からRequest LatencyはSREが管理するSLOから除外していました。
(SLOからは除外したものの、LatencyのモニタリングはSREチームとして継続的に実施していました。)
一方で、サービスの品質に直結する重要な指標であることは変わりないので、この部分は既存のSLO (HTTP request - Success rate) と同様にSLOを設定して、運用に乗せた上でLatencyの改善に取り組んでいく予定です。
開発チーム主導を念頭に置いたSLOの運用整備
SLOに関する日々の運用では、SRE側で完結するケースがほとんどでしたが、エラー増加に伴ってSLO (HTTP request - Success rate) が悪化した場合に開発チームに詳細を共有するケースもありました。
一連のイテレーション (SLOの推移の確認 → 調査 → 改善施策の実施 ...) を開発チームで完結できれば、リードタイムを最小限にしてサービス品質改善のサイクルを進めることができます。
その中で、SREチームとしては、開発チームがSLOの確認やそれに付随する調査などを主導的に実施できるように運用整備することが重要になってきます。
そのため、SLOの運用整備を目的に、開発チーム用のDatadog Dashboardの整備やエラー管理について内製ツールからSentryへの移行を進めています。
この部分はエラー管理など普段の運用業務も含めて、SLOに限定せずに施策を実施していく予定です。
終わりに
SLO運用の振り返り、振り返りを実施する中での気付きと今後の課題についてご紹介させていただきました。
以前のブログでも述べた通り、SLI/SLOは設定してゴールではなく、サービス運用の中でSLOを守りかつ状況に合わせて改善することが重要となります。
同じように、SLI/SLOを導入して運用・改善を進めている方々の参考になればと思います。