こんにちは! 2020年2月からSREチームにJoinしました木村です!
仕事をする上での座右の銘は「明日交通事故にあってもシステムと仕事を回せるようにすること」です。
基本に戻って始める。と表題では書いていますが、私元々はAWS職人でGCPに本格的にコミットしてからまだ3ヶ月位です!
なのでヒィヒィ?言いながらGCPのキャッチアップに努めているわけですが今回は過去にAWSで得たInfrastructure as Codeの知識とビザスクに入社してキャッチアップで培ったGCPの知識を元に基本に戻って始めるGCPのInfrastructure as Code再入門ということで書かせていただきます。
前回はGCPにCompute Engineのインスタンスとサービスアカウント作成までできましたので次はAnsibleを使って作成したインスタンスに対してProvisionを実行していきたいと思います。
思い返せば私がAnsibleを知って使い始めたのが確か8年前位でWikiPediaで調べてみるとほぼ初版リリース時と一緒位のタイミングから使い初めていたのに驚きでした(確か1.4?位から使っていた記憶)。
その他のGCPで基本に戻って始める実践 Infrastructure as code再入門シリーズはこちら
今回のGCPのInfrastructure as code再入門シリーズでのゴールイメージ
- TerraformでCompute Instanceを作成
- Compute Instanceに対してAnsibleでNginxをインストールする <= 今ココ
- AnsibleでProvisoningされたサーバーの状態をPackerでImage化

始める前に用意していただきたいもの
- GCPアカウント(初めての方はGCPの無料枠があります)
- GCP プロジェクト
- Homebrew
動作環境(ホストOS)
- ホストOS: Mac OSX
- Python 3.7.5
- Ansible (2.9.7)
動作環境(ゲストOS)
- Centos7
Ansibleを始める上で抑えておきたい用語
8年もの間ドラスティックに変わるインフラ環境に追随する為にAnsibleも様々な機能をアップデートをしてきてドキュメントも膨大になり初見ですとどこを探して良いかわかりづらくなってきたので、Ansibleを最初学ぶ上で知っておくべき用語をまとめてみました。
Playbook
Nginxのinstallやどのような設定をするのか?等対象サーバーに対しての実行する実際の振る舞いを記述するものです。
実務レベルになるとTop Level Playbook(Ansibleに最初に読み込ませるPlaybook)にroleを読み込ませて記述する形が一般的ではないでしょうか?
(Ansible BestPracticsでもrole or import playbookで記述を推奨しています)
# site.yaml
- name: Top Level Playbook
hosts:
# allと指定した場合は対象inventoryに対して全て適用
# inventoryは後で説明します
- all
- 192.168.xxx.xxx # 対象サーバーのIPアドレスでも可
# このような形でTop Level Playbook内で変数を記述することも可能
vars:
- ansible_ssh_port: 22
- ansible_python_interpreter: /usr/bin/python
# 変数ファイルをvars_filesに配置して変数を定義することも可能
vars_files:
- group_vars/secrets
- group_vars/all
roles:
# Playbookのパスを記載していく
- nginx/install
- nginx/configure
inventory
インフラストラクチャ内の管理対象ノード(サーバー)グループの設定を記述します。
ini形式、又はyaml形式で記述していきます。
下記の例でいうと、iniのセクションallと上記のTop Level Playbookのhostsセクションが紐付いて対象ノードが確定します。
# inventories/all
#ini形式の場合
[all]
192.168.xxx.xxx
webserver # これはssh_configの名前に紐付きます
上記の記載方法でも問題ないのですが、クラウドインフラの場合IPアドレスは動的に変わるのが前提ですし、ssh_configを記載するとssh_configの配布やメンテナンスが面倒になってくると思いますのでクラウドインフラの場合は Dynamic Inventoryの利用をおすすめします。
(Dynamic Inventoryの使い方に関しては後述します)
group_vars
先程のinvetnoryでallと記載したものが一つのグループになるのでその実行対象グループの変数群を指します。こちらもyaml形式での記述になります。
# group_vars/all
ssh_port: 12345
#
# gcp setting
#
gcp_zone: asia-northeast1-c
python_version: 3.7
他にも色々とあるのですが、最低限覚えておくのはこの位で大丈夫かと思います。
では実際にGCPで始めてみましましょう
まずはインストール作業から
GCloudSDKとAnsibleのインストール
brew cask install google-cloud-sdk
# ここらへんはpyenvでも良いです
brew install python3
pip install ansible==2.9.7
それぞれ確認します
$ gcloud --version
Google Cloud SDK 289.0.0
$ ansible-playbook --version
ansible-playbook 2.9.7
$ python --version
Python 3.7.5
前回作成したCompute Engine Instanceを確認する
もし前回のインスタンスを削除していたならばTerraformで再度作成してください。
あら不思議、元の状態をいとも簡単に復元出来ます。
GCP Console => IAMの確認
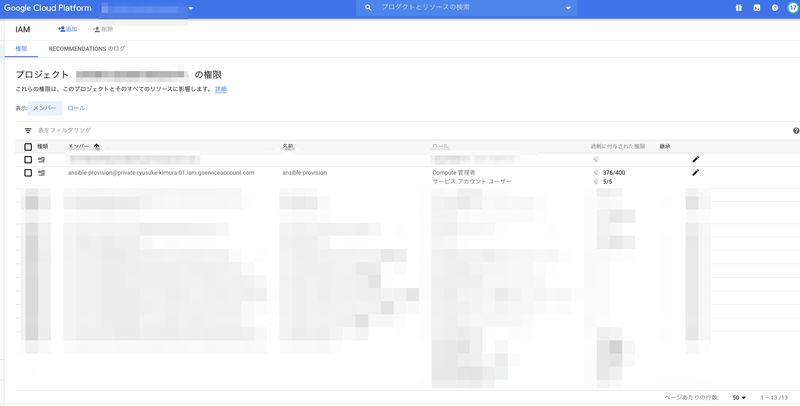
Ansible-provisionというサービスアカウントユーザーがいることを確認してください
Ansibleのベストプラクティスに沿ったディレクトリ構成を作成する
Ansible公式のベストプラクティスのディレクトリレイアウトはこちら
(今回は若干変えています)
$ tree .
.
├── ansible.cfg
├── site.yml
├── group_vars
│ └── all
├── inventories
│ └── dev.gcp.yml
├── logs
│ └── .gitkeep
└── saecrets
└── gcp-key-ansible-sa.json
ansible.cfgの設定をPython3にする
Ansibleを実行する上での注意事項ですが、AnsibleはホストOS(今回でいうとMac)で実行するPythonのバージョンとリモートサーバー(今回で言うとCentos7)のバージョンは一致しません。
Ansibleを実行するとplaybbookの解釈はホストOSのPython(今回で言うとPython3)が解析をし、リモートサーバーにPlaybookの命令で必要なファイル群をSSHで転送します。その後Ansibleで設定されているリモートサーバーのPythonのPATHを検索して対象PATHのPythonを実行します。(転送されるファイル群はPythonファイルです)
今回のCentos7の例でいうとデフォルトのPythonのPATHは/usr/bin/pythonで
対象パスのPythonはPython2系です。
まぁそれでも問題はないのですが、Python2はサポートが切れた事ですし今回はリモートサーバー側もPython3にしてみましょう。
ansible.cfgを記述する
# ansible.cfg
[defaults]
# ついでにansibleの実行時のlogのパスも追加しておきます
log_path = ./logs/ansible.log
#
# これ指定しないとPython3に向かないので注意
#
interpreter_python = /usr/bin/python3
[inventory]
# こちらは後述するDynamic Inventoryの部分で説明します
enable_plugins = gcp_compute
作成したCompute InstanceにPython3をインストールする
ansible.cfgで設定したinterpreter_pythonのパスと一致しているか確認します。
# 作成した Compute InstanceにSSH接続をします
$ gcloud compute ssh --zone 'asia-northeast1-c' 'ansible-example' --project {your gcp projectid}
$ sudo yum install python3
$ which python3
/usr/bin/python3
Dynamic Inventoryの設定を行う
少し前に触れましたDynamic Inventoryですが、名前の通り動的にInventoryを作成する機能です。
以前はAWSのDynamic Inventoryのようにgcp.pyというPythonファイルを指定して実行していたようですが(ごめんなさい。私はその頃のGCP Dynamic Inventoryは知らないです)、今はyaml形式でGCPの設定を記載していきます。
余談ですがAnsibleではinventoryの引数に対してpython実行ファイルを指定することができて
ansible-playbook --inventory foo.pyその中身のレスポンスをjson形式で返すことによって動的に対象ホストを変えることができます。
# レスポンス Keyにhosts名 valueに対象ホストのIPアドレス等
{
"all" : [ "192.168.xxx.xxx", "192.167.xxx.xxx" ]
}
話が逸れました。以下がgcpでDynamic Inventoryを実行する場合の例です。
# inventories/dev.gcp.yml
# 先程ansible.cfgのinventoryセクションで指定したgcp_computeモジュールを使う設定です
plugin: gcp_compute
projects: {your gcp projectid}
regions:
- asia-northeast1-c
filters: []
# ansibleの実行ユーザーはサービスアカウント
auth_kind: serviceaccount
# サービスアカウントのkeyファイルのパス
service_account_file: secrets/gcp-key-ansible-sa.json
keyed_groups:
- prefix: gcp
key: labels
今回はGCPのOSログイン機能を使いリモートサーバーでのAnsibleの実行ユーザーはサービスアカウントという想定になります。
またkeyed_groupsですがGCPのlabel(AWSでいうtag)とAnsibleのHost名が紐づくように設定しています。
AWSのtagもそうですが、クラウドリソースのグルーピングにはうってつけ(おそらくコストの紐付け等で使うケースが多いですが)ですしInstance名等はサービス内部で参照されていて変更する事が難しい場合が多いので、labelを活用してみてください。
GCP Compute inventory Plugins の詳細は公式ドキュメントをご確認ください。
サービスアカウントのキーファイルを作成する
前回のTerraformですでにサービスアカウントユーザーは作成しているのでサービスアカウントのキーファイルの作成とOSログインに必要な設定を記述します
# 作成したサービスアカウントのキーファイルを作成する
$ gcloud iam service-accounts keys create \
--project {your gcp projectid} \
secrets/gcp-key-ansible-sa.json \
--iam-account=ansible-provision@{your gcp projectid}.iam.gserviceaccount.com
# サービスアカウントの情報を間違ってコミットしないように.gitignoreに追加
echo "secrets/" > .gitignore
# サービスアカウント用のSSH鍵を作成する
$ ssh-keygen -f secrets/ssh-key-ansible-sa
# 作成したSSH鍵の公開鍵をos-loginに登録する
$ gcloud compute os-login ssh-keys add \
--project {your gcp projectid} \
--key-file=secrets/ssh-key-ansible-sa.pub
# 作成したサービスアカウントの認証を通す
$ gcloud auth activate-service-account \
--project {your gcp projectid} \
--key-file=secrets/gcp-key-ansible-sa.json
これでサービスアカウントの作成からOSログインの設定迄は完了です。
サービスアカウントからCompute InstanceにSSH接続ができるか確認する
実際にサービスアカウントからSSHの接続ができるか確認してみましょう。
OSログインに登録したサービスアカウント名はsa_{サービスアカウントID}というユーザー名で登録されています。
$ gcloud iam service-accounts describe \
ansible-provision@{your gcp projectid}.iam.gserviceaccount.com \
--project {your gcp projectid} \
--format='value(uniqueId)'
# アカウントIDが取得出来ます
123456789ではsshで接続してみましょう
ssh -i secrets/ssh-key-ansible-sa sa_123456789@{Your PublicIPAdress}接続出来たらリモートサーバーに接続するユーザー作成の準備は完了です。
Top Level Playbookを記述する
では作成したサービスアカウントユーザーでAnsibleの接続ができるか確認してみましょう。
Top Level Playbookを記述します。
まずはシンプルにリモートサーバーに対してshellでpwdを実行します。
# site.yml
- name: Top Level Playbook Sample
hosts:
- "gcp_service_type_web"
tasks:
- shell: pwd
hostの名前ですが、Compute Instanceを作成した際につけたlabelsの名前を指定します。gcp_{key-value}というhost名を指定するとGCP inventory Pluginが作成したlabel名とhostを自動で紐付けてくれます。
余談ですが、labelにハイフン(-)が含まれる場合Ansibleはhost名をアンダーバー(_)に変換しますのでご注意ください。
Ansibleで対象サーバーの確認をする
まずは慎重に対象サーバーが合っているか?を確認します。
ansible-playbookのオプションの--list-hostsを指定するとAnsibleは実際にtasksを実行せずに対象のリモートサーバーがどれか?の結果を返して終了します。
$ ansible-playbook \
--list-hosts \
--inventory=inventories/dev.gcp.yml \
--private-key secrets/ssh-key-ansible-sa \
--user sa_123456789 \
--diff \
-v \
site.yml
出力結果
playbook:site.yml
play #1 (gcp_service_type_web): Top Level Playbook Sample TAGS: []
pattern: ['gcp_service_type_web']
hosts (1):
xx.xx.xxx.xxxhostsで出力されているIPアドレスが実行したいリモートサーバーのIPアドレスと一致しているかを確認してください
ではAnsibleを実行してみましょう
tasksで定義したshell: pwdを実行するには先程のコマンドから--limit-hostsを抜きます
$ ansible-playbook \
--inventory=inventories/dev.gcp.yml \
--private-key secrets/ssh-key-ansible-sa \
--user sa_123456789 \
--diff \
-v \
site.yml
出力結果
Using /path/to/ansible.cfg as config file
PLAY [Top Level Playbook Sample] ****************************************************************************************************************************************************************
TASK [Gathering Facts] **************************************************************************************************************************************************************************
ok: [xx.xx.xx.xx]
TASK [shell] ************************************************************************************************************************************************************************************
changed: [xx.xx.xx.xx] => {"changed": true, "cmd": "pwd", "delta": "0:00:00.003370", "end": "2020-05-15 20:58:57.084198", "rc": 0, "start": "2020-05-15 20:58:57.080828", "stderr": "", "stderr_lines": [], "stdout": "/home/sa_123456789", "stdout_lines": ["/home/sa_123456789"]}
PLAY RECAP **************************************************************************************************************************************************************************************
xx.xx.xx.xx : ok=2 changed=1 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0 無事pwdの結果が返ってきました
まとめ
今回はAnsibleを使ってProvisioningをする迄。というのをやっていきました。
次回は実際の書き方について説明していきたいと思います。
Ansibleのドキュメントが大分膨大になってきたので最初取っつきづらいかもしれませんが、上記の基本を抑えておけば後は必要に応じてドキュメントを読み直せば良いかと思います。
エンジニア積極採用中
ビザスクでは一緒に働くエンジニアさん積極採用中です。
時期的にビデオ通話での面談になると思うので、ビザスクにちょっとでも興味のある方はいつもより気軽にお話を聞きに来ることができるかなと思います。
- エンジニア採用ページ: https://visasq.co.jp/engineer-recruitment
- ビザスクの中の様子はこちらから >> https://square.visasq.com/