アドバイザー開発チームのぐりこ ( @glico800 ) です。
最近ふと登録したけど全く使われていないカスタム絵文字ってどれくらいあるのだろうと思い、Python と Slack API を使って調べようとしたら、意外と参考になるコードが少なかったり、Slack App 周りの仕様が変わっていたりして困ったので、備忘録も兼ねてどうやって調べたのかを一部紹介したいと思います。
気になる調査結果は(企画が通れば)後日ビザスクエアの方で紹介できればと考えているので、お楽しみに!
2021.04.30 追記
無事にビザスクエアに掲載されました!🎉
https://square.visasq.com/n/n18ef6083529d
やりたかったこと
ビザスクのワークスペース内のパブリックチャンネルから絵文字の利用頻度の情報を取得して、過去1年間で全く使われなかったカスタム絵文字一覧を調べたい。
おまけでチャンネルごとによく使われている絵文字も調べられるようにしたい。
前提条件
- Slack上の権限は「メンバー」を想定
- 管理者権限がある場合は管理画面からメッセージ一覧を出力できる
- 権限上、パブリックチャンネルのみを対象に調査する
- 継続的に利用するものではないので、あまり自動化はしない
作ったもの
Slack上の絵文字利用頻度を調べるコンソールアプリを作りました。
使われていない絵文字一覧については、手動でコンソールから実行して標準出力上で結果を確認する仕様です。Slack Bot として作り込むことも考えたのですが、そんなに何度も使うものではないので、簡単にコンソールアプリにしました。
基本的な仕組みは利用頻度の高い絵文字を調べる場合と同じなので、以下のようなEmojiランキングの機能もおまけで付けました。
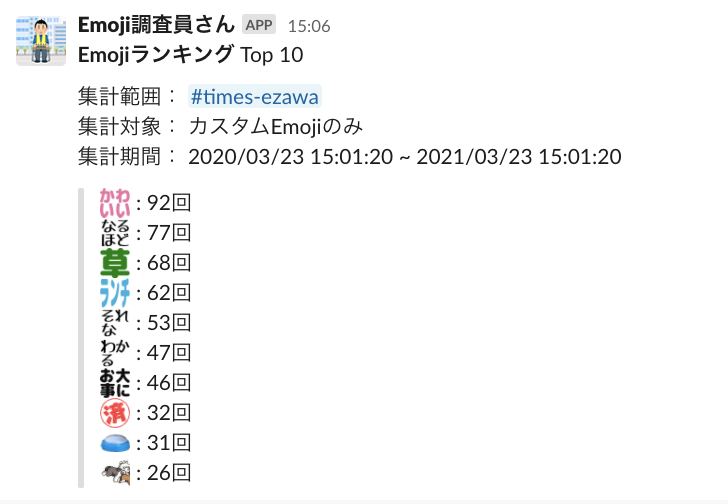
できることは
- 使っていない絵文字一覧をコンソール上に表示
- 利用回数を指定して集計できる
(例:利用回数0回の絵文字一覧、利用回数2回以下の絵文字一覧など) - 検索範囲は全パブリックチャンネル
- 検索対象はカスタム絵文字のみ
- 利用回数を指定して集計できる
おまけ機能の方は
- 絵文字の利用頻度Topランキングを Slack Bot として特定のチャンネルに投稿
- 何位まで表示するかを選べる(例:Top 10、Top 30 など)
- 検索範囲は特定のチャンネルか全パブリックチャンネルか選べる
- 検索対象はカスタム絵文字のみかすべての絵文字か選べる
拙いところのあるコードですが、ご参考まで(ちゃんとレビューしてもらったので、基本的なところは大丈夫なはず!)
https://github.com/ezawa800/emoji-survey-san
使ったもの
- Python 3.8.7
- Python Slack SDK 3.4.2
( https://github.com/slackapi/python-slack-sdk ) - python-dateutil 2.8.1
( https://pypi.org/project/python-dateutil/ )
やること
- Slack App の初期設定〜環境構築
- WebClient の初期化
- パブリックチャンネル一覧の取得
- カスタム絵文字一覧の取得
- チャンネルごとのメッセージ一覧の取得
- メッセージ一覧から絵文字情報を抽出して集計
- 集計データから使っていない絵文字を抽出する
全部を詳細に紹介するとかなり長くなってしまいそうなので、各工程を簡単にご紹介します。
Slack App の初期設定〜環境構築
https://api.slack.com/apps へアクセスして Create New App ボタンからアプリを作成します
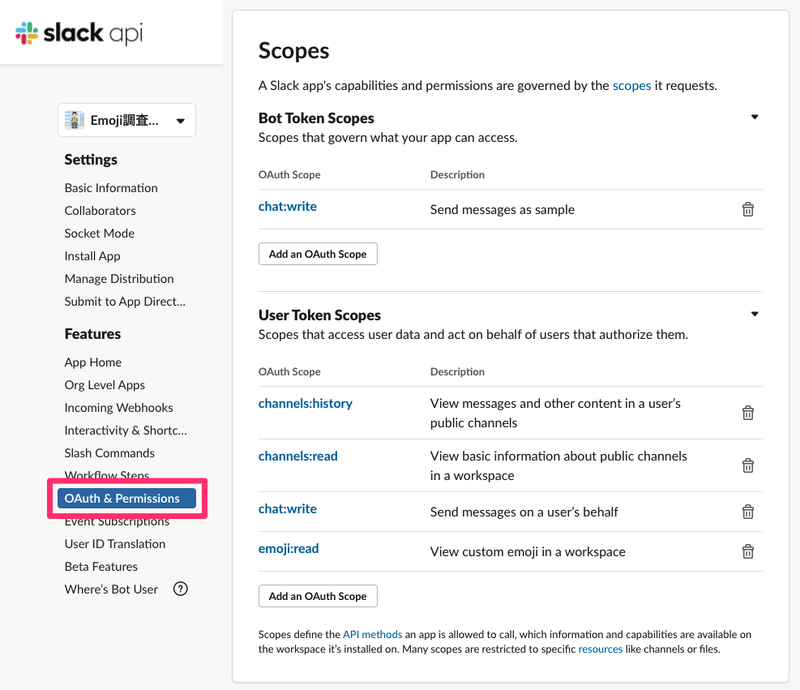
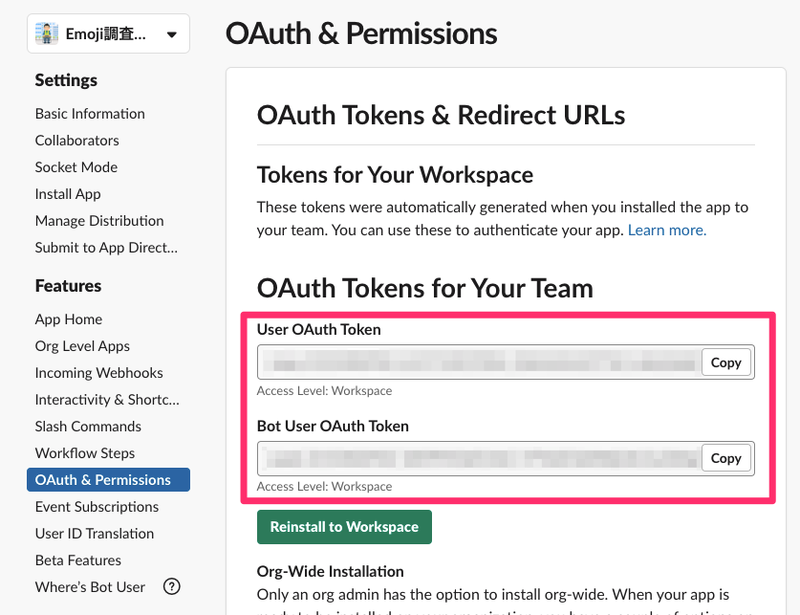
左側の OAuth & Permissions から以下の通り権限設定をします。
このとき Bot Token Scopes の方に channels:history などを設定してしまうと、Bot が参加しているチャンネルの情報しか取得できないので注意しましょう。
ページ上部にある Install to Workspace ボタンを押してアプリを追加します。
アプリ追加に認証が必要な場合は、 Install to Workspace ボタンの代わりに Request to Install ボタンが表示されます。
アプリが追加されると2つの Token が発行されるので、手元に控えておいてください。
次に Python の開発環境を構築していきます。
$ mkdir emoji_survey_san
$ cd emoji_survey_san
$ pyenv install 3.8.7
$ pyenv local 3.8.7
$ python -V
Python 3.8.7
$ pip install slack_sdk
$ pip install python-dateutil以下のメッセージを投稿するサンプルコードが動けば環境構築は完了です。
※python-deteutil はサンプルコードで使っていませんが後で使います。
# sample.py
# run: SLACK_BOT_TOKEN="Bot User OAuth Token" python sample.py
import o
from slack_sdk import WebClient
from slack_sdk.errors import SlackApiError
client = WebClient(token=os.environ['SLACK_BOT_TOKEN'])
try:
response = client.chat_postMessage(channel='#times-ezawa', text="Hello world!")
assert response["message"]["text"] == "Hello world!"
except SlackApiError as e:
# You will get a SlackApiError if "ok" is False
assert e.response["ok"] is False
assert e.response["error"] # str like 'invalid_auth', 'channel_not_found'
print(f"Got an error: {e.response['error']}")WebClient の初期化
各メソッドで利用する WebClient は事前に取得しておきます。
※より汎用的にするなら各メソッドに引数として渡す方がよいかもしれません。
注意点としては token をコード内に書いてしまうと漏洩する危険があるので、token は実行時に入力を受け付ける形にしておくのが安全です。本コードでは input 関数を使って入力するようになっています。
from slack_sdk import WebClient
client = None
def init_web_client(token: str) -> WebClient:
global client
if client is not None:
return client
client = WebClient(token=token)
return client
def main() -> None:
token = input("User OAuth Token: ")
init_web_client(token)
# only for post message
bot_token = input("Bot User OAuth Token: ")
bot_client = WebClient(token=bot_token)
if __name__ == "__main__":
main()パブリックチャンネル一覧の取得
チャンネル名からチャンネルIDを調べるための一覧データです。
全パブリックチャンネルのメッセージを順番に取得していったり、入力されたチャンネル名を検証・チャンネルIDに変換するのに使います。
conversations.list はデフォルトでパブリックチャンネルのみを取得するようになっているので、特別チャンネルの種類に関する引数などはなくても大丈夫です。
import time
from http.client import IncompleteRead
from slack_sdk.errors import SlackApiError
# ref. https://api.slack.com/docs/rate-limits
SLEEP_BUFFER = 0.1
SLEEP_TIER1 = 60 / 1 + SLEEP_BUFFER
SLEEP_TIER2 = 60 / 20 + SLEEP_BUFFER
SLEEP_TIER3 = 60 / 50 + SLEEP_BUFFER
SLEEP_TIER4 = 60 / 100 + SLEEP_BUFFER
RETRY = 3
public_channel_map = None
def get_public_channel_map() -> dict:
global public_channel_map
if public_channel_map is not None:
return public_channel_map
channel_map = {}
for _ in range(RETRY):
try:
cursor = None
while True:
response = client.conversations_list(
exclude_archived=True,
limit=1000,
cursor=cursor
)
channel_map.update(
{channel["name"]: channel["id"] for channel in response["channels"]} # noqa: E501
)
has_more = response["has_more"]
if has_more:
cursor = response["response_metadata"]["next_cursor"]
time.sleep(SLEEP_TIER2)
else:
break
except SlackApiError as e:
print("Error: ", e.response["error"])
except IncompleteRead as e:
print("IncompleteRead Exception: ", e)
except ConnectionError as e:
print("ConnectionError: ", e)
else:
break
else:
print("Failed to get public channel list.")
return None
public_channel_map = channel_map
return public_channel_mapSlack API は各メソッドごとに分間リクエスト数に制限があるので、適宜 sleep を挟んでいます。
これを忘れてリクエスト数上限に達してしまうと、しばらくの間リクエストができなくなるので注意が必要です。上限は各メソッドの公式ドキュメントに記載されています。
詳しくは https://api.slack.com/docs/rate-limits
import time
# ref. https://api.slack.com/docs/rate-limits
SLEEP_BUFFER = 0.1
SLEEP_TIER1 = 60 / 1 + SLEEP_BUFFER
SLEEP_TIER2 = 60 / 20 + SLEEP_BUFFER
SLEEP_TIER3 = 60 / 50 + SLEEP_BUFFER
SLEEP_TIER4 = 60 / 100 + SLEEP_BUFFER
...
time.sleep(SLEEP_TIER1)またチャンネル名やメッセージなどは一度に最大1000件までしか取得できないので、取得結果に含まれる next_cursor の値を使って数回に分けてリクエストします。
channel_map = {}
cursor = None
while True:
response = client.conversations_list(
exclude_archived=True,
limit=1000,
cursor=cursor
)
channel_map.update(
{channel["name"]: channel["id"] for channel in response["channels"]} # noqa: E501
)
has_more = response["has_more"]
if has_more:
cursor = response["response_metadata"]["next_cursor"]
time.sleep(SLEEP_TIER2)
else:
breakリクエストが失敗したときに処理が止まると今までの処理が無駄になってしまって悲惨なので、簡易的にリトライするようになっています。
( https://pypi.python.org/pypi/retry/ を使ってもできそう(未検証) )
for _ in range(3): # 最大実行回数
try:
do_something() # 失敗する可能性がある処理
except Exception as e:
pass # 失敗時の処理
else:
break # 失敗しなかった時はループを抜ける
else:
pass # リトライが全部失敗した時の処理カスタム絵文字一覧の取得
ワークスペースに登録されているカスタム絵文字の一覧データです。
メッセージに含まれている絵文字がカスタム絵文字かどうか判定するのに使います。
import time
from http.client import IncompleteRead
from slack_sdk.errors import SlackApiError
# ref. https://api.slack.com/docs/rate-limits
SLEEP_BUFFER = 0.1
SLEEP_TIER1 = 60 / 1 + SLEEP_BUFFER
SLEEP_TIER2 = 60 / 20 + SLEEP_BUFFER
SLEEP_TIER3 = 60 / 50 + SLEEP_BUFFER
SLEEP_TIER4 = 60 / 100 + SLEEP_BUFFER
RETRY = 3
custom_emoji_names = None
def get_custom_emoji_names() -> list:
global custom_emoji_names
if custom_emoji_names is not None:
return custom_emoji_names
for _ in range(RETRY):
try:
response = client.emoji_list()
except SlackApiError as e:
print("Error: ", e.response["error"])
except IncompleteRead as e:
print("IncompleteRead Exception: ", e)
except ConnectionError as e:
print("ConnectionError: ", e)
else:
break
else:
print("Failed to get custom emoji list.")
return None
custom_emoji_names = list(response["emoji"].keys())
return custom_emoji_namesチャンネルごとのメッセージ一覧の取得
チャンネルごとのメッセージ一覧データです。
この処理が割とやっかいで、Slack API の仕様変更によって channels.history メソッドの結果に返信が含まれなくなったので、返信は個別に取得する必要があります。
import time
from datetime import datetime
from http.client import IncompleteRead
from dateutil import relativedelta
from slack_sdk.errors import SlackApiError
MESSAGE_LIMIT = 1000
# ref. https://api.slack.com/docs/rate-limits
SLEEP_BUFFER = 0.1
SLEEP_TIER1 = 60 / 1 + SLEEP_BUFFER
SLEEP_TIER2 = 60 / 20 + SLEEP_BUFFER
SLEEP_TIER3 = 60 / 50 + SLEEP_BUFFER
SLEEP_TIER4 = 60 / 100 + SLEEP_BUFFER
RETRY = 3
# survey priod
LATEST = datetime.now()
OLDEST = LATEST - relativedelta.relativedelta(years=1)
def get_messages(channel_name: str, contains_reply: bool = True) -> list:
channel_id = get_public_channel_id_by_name(channel_name)
result = []
for _ in range(RETRY):
try:
cursor = None
while True:
response = client.conversations_history(
channel=channel_id,
limit=MESSAGE_LIMIT,
cursor=cursor,
latest=LATEST.timestamp(),
oldest=OLDEST.timestamp()
)
print(f" -> {len(response['messages'])} messages fetched.")
messages = response["messages"]
result.extend(messages)
if contains_reply:
for message in messages:
if "reply_count" not in message:
continue
thread_ts = message["thread_ts"]
replies = get_replies(channel_name, thread_ts)
if replies is None:
raise SlackApiError(
f"Failed to get replies. {channel_name}, {thread_ts}"
)
result.extend(replies)
has_more = response["has_more"]
if has_more:
cursor = response["response_metadata"]["next_cursor"]
time.sleep(SLEEP_TIER3)
else:
break
time.sleep(SLEEP_TIER3)
except SlackApiError as e:
print("Error: ", e.response["error"])
except IncompleteRead as e:
print("IncompleteRead Exception: ", e)
except ConnectionError as e:
print("ConnectionError: ", e)
except:
print("Unexpected Error")
else:
break
else:
print(f"Failed to get messages in {channel_name}.")
return None
return result
def get_replies(channel_name: str, thread_ts: str) -> list:
channel_id = get_public_channel_id_by_name(channel_name)
result = []
for _ in range(RETRY):
try:
cursor = None
while True:
response = client.conversations_replies(
channel=channel_id,
ts=thread_ts,
limit=MESSAGE_LIMIT,
cursor=cursor,
latest=LATEST.timestamp(),
oldest=OLDEST.timestamp()
)
print(f" ---> {len(response['messages'])} replies fetched.")
replies = [message for message in response["messages"] if message["ts"] != thread_ts] # noqa: E501
result.extend(replies)
has_more = response["has_more"]
if has_more:
cursor = response["response_metadata"]["next_cursor"]
time.sleep(SLEEP_TIER3)
else:
break
time.sleep(SLEEP_TIER3)
except SlackApiError as e:
print("Error: ", e.response["error"])
except IncompleteRead as e:
print("IncompleteRead Exception: ", e)
except ConnectionError as e:
print("ConnectionError: ", e)
except:
print("Unexpected Error")
else:
break
else:
print(f"Failed to get replies in {channel_name}.")
return None
return resultメッセージ取得処理はとても時間がかかるので、途中で止まってしまうと特に悲惨です。なので、本当は良くないのですが、やむを得ず想定しない例外のときも一旦再試行するようになっています。
except:
print("Unexpected Error")取得したメッセージに返信があるかどうかは reply_count という値を見ればわかるので、その値の有無をみて取得処理をしています。( thread_ts の有無でみてもよいかもしれません)
また、返信のデータを取得するのがとても時間がかかるので、メソッドの引数で取得するか選択できるようにしています。
if contains_reply:
for message in messages:
if "reply_count" not in message:
continue
thread_ts = message["thread_ts"]
replies = get_replies(channel_name, thread_ts)
if replies is None:
raise SlackApiError(
f"Failed to get replies. {channel_name}, {thread_ts}"
)
result.extend(replies)conversations.replies の結果には返信以外に、元のメッセージが含まれるため、ts の値を使って返信かどうか判定する処理が入っています。
元のメッセージは ts と thread_ts の値が同じなのでそれで判定していますが、もっといい方法があるかもしれません。
response = client.conversations_replies(
channel=channel_id,
ts=thread_ts,
limit=MESSAGE_LIMIT,
cursor=cursor,
latest=LATEST.timestamp(),
oldest=OLDEST.timestamp()
)
print(f" ---> {len(response['messages'])} replies fetched.")
replies = [message for message in response["messages"] if message["ts"] != thread_ts] # noqa: E501
result.extend(replies)メッセージ一覧から絵文字情報を抽出して集計
メッセージ一覧のデータから絵文字の情報を取得します。
def get_custom_emoji_count(channel_name: str) -> dict:
custom_emoji_names = get_custom_emoji_names()
result = {}
messages = get_messages(channel_name)
if messages is None:
print(f"Failed to get emoji count in {channel_name}")
return None
for message in messages:
# count in text
for block in message.get("blocks", []):
for elem in block.get("elements", []):
for e in elem.get("elements", []):
if e["type"] == "emoji":
emoji_name = e["name"]
if emoji_name in custom_emoji_names:
total = result.get(emoji_name, 0) + 1
result.update({emoji_name: total})
# count in reactions
if "reactions" not in message:
continue
for reaction in message["reactions"]:
emoji_name = reaction["name"]
emoji_count = reaction["count"]
if emoji_name in custom_emoji_names:
total = emoji_count + result.get(emoji_name, 0)
result.update({emoji_name: total})
return result
メッセージ中の絵文字は blocks という値の中で分割されて格納されているので、それを調べるとカウントできます。
blocks という値の有無がよくわからなかったので、get() メソッドを利用しながらループを回しています。
# count in text
for block in message.get("blocks", []):
for elem in block.get("elements", []):
for e in elem.get("elements", []):
if e["type"] == "emoji":
emoji_name = e["name"]
total = result.get(emoji_name, 0) + 1
result.update({emoji_name: total})リアクションの絵文字のカウントは上記よりもシンプルで、単に reactions の値をみるだけです。
# count in reactions
if "reactions" not in message:
continue
for reaction in message["reactions"]:
emoji_name = reaction["name"]
emoji_count = reaction["count"]
total = emoji_count + result.get(emoji_name, 0)
result.update({emoji_name: total})カスタム絵文字のみに絞って集計する場合は、上記のカウント時に以下のようにカスタム絵文字一覧データに含まれるかどうかを判定するだけです。
custom_emoji_names = get_custom_emoji_names()
...
emoji_name = reaction["name"]
emoji_count = reaction["count"]
if emoji_name in custom_emoji_names:
total = emoji_count + result.get(emoji_name, 0)
result.update({emoji_name: total})get_emoji_count() メソッドは特定のチャンネルを調べるようなっているので、全チャンネルの調べるためにチャンネル一覧をループさせて集計します。
このときログチャンネルなどメッセージ数が多くてデータ取得に時間がかかるチャンネルは除外しておくと処理が少しだけ節約できます。
EXCLUDE_CHANNEL_PATTERN = ('log-', 'log_')
def get_custom_emoji_count_in_all_public_channel() -> dict:
channel_map = get_public_channel_map()
result = {}
channel_names = [
name for name in channel_map.keys() if not name.startswith(EXCLUDE_CHANNEL_PATTERN)
]
for index, channel_name in enumerate(channel_names):
print(
f"surveying in {channel_name} ({index + 1}/{len(channel_names)})..."
)
sub_result = get_custom_emoji_count(channel_name)
if sub_result is None:
print("Failed to get custom emoji count in all channel.")
return None
for emoji_name, count in sub_result.items():
result.update({emoji_name: count + result.get(emoji_name, 0)})
return resultここまでで以下のような形式の絵文字利用頻度のデータが取得できます。
{
'emoji1': 7,
'emoji2': 10,
'emoji3': 9,
...
}集計データから使っていない絵文字を抽出する
最後に前述の絵文字利用頻度データを整理して、使っていない絵文字一覧を取得することができます。
def get_unused_custom_emojis(emoji_count: dict, limit: int = 3) -> dict:
result = {}
names = get_custom_emoji_names()
all_count = {name: emoji_count.get(name, 0) for name in names}
for i in range(limit + 1):
result[i] = [name for name, count in all_count.items() if count == i]
return result絵文字の利用頻度データには1度も使われなかった絵文字の情報は含まれないので、先にすべてのカスタム絵文字のカウント情報を取得します。
names = get_custom_emoji_names()
all_count = {name: emoji_count.get(name, 0) for name in names}all_count の中から特定の利用頻度の絵文字名を抽出していくと、使っていない絵文字の一覧を取得することができます。
for i in range(limit + 1):
result[i] = [name for name, count in all_count.items() if count == i]出来上がるデータはこんな感じです。
例)対象期間内では emoji4 と emoji5 が1度も使われず、emoji6-8 が1度だけ使われていた場合
{
0: ['emoji4', 'emoji5'],
1: ['emoji6', 'emoji7', 'emoji8']
}あとはこれを必要な形式に変換すれば完成です。
例)
ここ1年で使われなかったカスタム絵文字一覧
1度も使われなかった絵文字
:emoji4: :emoji5"
1度だけ使われた絵文字
:emoji6: :emoji7: :emoji8
使われなかった絵文字はワークスペースによってはかなりの数になるので、Slack API で投稿すると複数のメッセージに自動で分割されてしまったり、gif形式の絵文字が多数あってチャンネルを開くのに時間がかかるようになってしまったりするので、基本的にコンソール上に表示して手元で整形してから投稿するのがおすすめです。
まとめ
- 使っていないカスタム絵文字はよく使う絵文字の調査方法の応用で比較的簡単にできた
- APIリクエストには分間リクエスト数の上限があるので注意
- ただし、返信も含めて全チャンネルの調査する場合は、実行にとても時間がかかるので、エラーハンドリングなどに注意が必要
ちなみに Slack API を使っての全チャンネル検索は処理が本当に長時間におよぶので、可能なら管理者からメッセージ一覧データを出力してもらうか、返信を含まずに集計するのがおすすめです。
もし記載したコードに不具合などあれば教えてもらえると嬉しいです。