はじめに
こんにちは。SREチームの西川です。
現在、ビザスクではサービスのインフラ基盤のリプレイスに伴い、Sentry+Datadogを用いたサービス監視体制を整備しています。
その中で、継続的に抱えていた「運用の属人化」という課題に対して、ツール面からアプローチできないかという思いがありました。
今回は、「運用の属人化」に対する課題意識、ツール利用の観点から属人化へのアプローチについてまとめます。
課題意識
ビザスクでのサービス監視系の運用作業 (e.g. エラー対応) に関しては、各サービスチーム+SREチームで実施しています。
上記の運用作業を行う中で、下記のような課題が挙がっていました。
- エラー対応などの運用作業が特定のメンバーに集中している
- 社内からの問い合わせ・事象調査の際に、複数のツールの使い分けが必要になったり、調査に必要な情報にリーチしづらいケースがある
- エラー対応の過去ログが流れてしまい、過去の知見 (e.g. 調査方法、対処法) を活用できない
緊急度の高い対応は経験の浅いメンバーにデリゲートしづらい点やメンバーの対応可否が時々によって変わるなど、対応を難しくする側面もありつつ、これらの課題に具体的なアプローチが実施できない状態が続いていました。
SECIモデルによる現状把握
新環境でのサービス監視の整備にあたり、上記の課題に対しても何か取り組むことはできないか? という思いを持っていました。
そのために、施策の前段階として現状の課題・取り組みを踏まえたチームとしての状態を把握するために、SECIモデルを利用しました。
SECIモデルとは、一橋大学の野中郁次郎教授が提唱した経営における知識活用に関するモデルで、ナレッジ・マネジメントの考え方のベースとなったものです。
SECIモデルは下記の4つのプロセスから構成されます。
- 共同化(Socialization): 共通体験をもとに暗黙知を共感・共有する
- 表出化(Externalization): その暗黙知を言葉や図表などの形式知に変換する
- 連結化(Combination): 複数の形式知を組み合わせて新たな形式知を生み出す
- 内面化(Internalization): 連結された形式知を学習・実践することで暗黙知として体得する
このうち、共同化に関して、2人1組で1週間交代で運用を回していく「運用週」という仕組みが一部のチームで実施されており、各チーム単位で暗黙知の共有は少しづつ進んでいます。
(運用週に関しては、過去のテックブログに記載があるので、興味がある方はそちらもどうぞ。)
https://tech.visasq.com/operation-datadog-dashboard/
このことから新環境では、個々人のノウハウを形式知へと変換する「表出化」とそれらの知見を集積・結合させる「連結化」のプロセスが必要になり、それを念頭に置いた整備を進めるべきと考えました。
Sentry + Datadogの導入
上記を踏まえた上で、監視用途で新環境で利用するSentryとDatadogの2種類のツールに関する説明をします。
Datadogに関しては、既存システムの監視でも利用しており、SLOの導入記事でもDatadogの採用理由について少し触れています。
https://tech.visasq.com/slo-adoption/
メトリクス・ログなどの監視項目を横断的に見ることができ、DashboardなどのViewのカスタマイズ性も高いため、「何の項目・指標をどのように見るのか」という暗黙的なノウハウをDashboardなどに落とし込むことができます。
Sentryに関しては、エラーイベントの詳細ページの情報の充実度、エラーの調査・対応結果をエラーイベントに紐付くActivityとして残せる点が魅力的です。
既存環境では、エラー管理に関しては内製ツールでのSlack通知に留まっており、エラーの対応ログがSlackやドキュメントツールに分散しやすい状態になっていました。
そのため、エラー調査のコストも低く、調査・対応結果の知見をSentryのActivityに集約できるという点で、Sentryは適切なツールであると考えました。
すでにDatadogは全社的に、Sentryは一部の既存サービスで導入済みの状態でしたが、Sentryに関しては新環境においては全体導入を決めました。
では、どのような機能が具体的に活用できるかについてもまとめていきます。
(Sentry) エラーイベントの詳細情報
弊社は、BackendはPython (Django) で実装しているため、SentryのDjango Integrationを前提とした内容になります。
https://docs.sentry.io/platforms/python/guides/django/
Sentryは、発生したエラーイベントに対して、デフォルトで取得できる情報が充実しています。
イベントに紐づくメタデータ (e.g. 環境情報、Request path) であるtagはもちろんのこと、エラー発生時に実行されていた関数、HTTP request、クエリなどの情報もbreadcrumbsから確認できます。
https://docs.sentry.io/product/issues/issue-details/breadcrumbs/
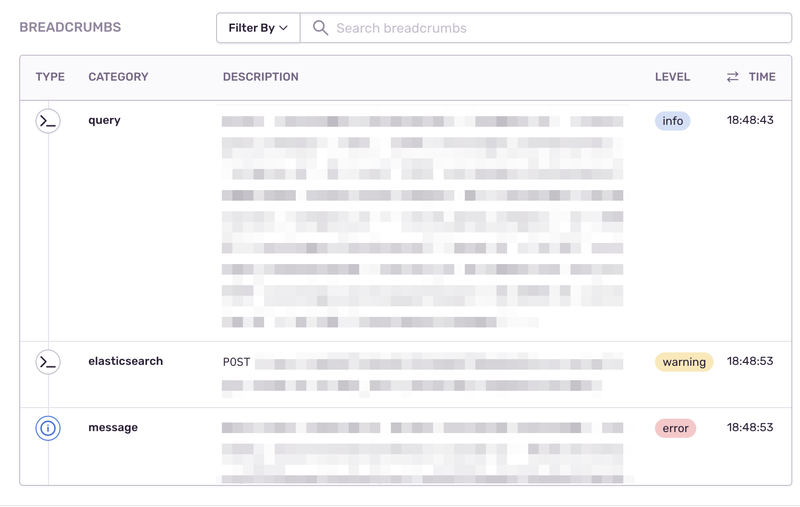
また、エラーイベントに対して、ユーザー側で定義したcustom tagをイベントのメタデータとして渡すことも可能です。
Sentry SDKを利用してkey-valueの形式で任意の値を渡すことで、ユーザーの認証状態や影響を受けたユーザーのIDなど調査・対応に必要な情報をcustom tagとしてSentry側に渡すことができます。
https://docs.sentry.io/platforms/python/enriching-events/scopes/
エラーイベントの情報をリッチにすることで、「エラー対応はSentryだけで完結できる」状態にできればエラー対応自体のハードルも一段階下がります。
少なくとも、複数のツールの利用を前提にしている状態と比較すると、対応フロー自体が簡潔になります。
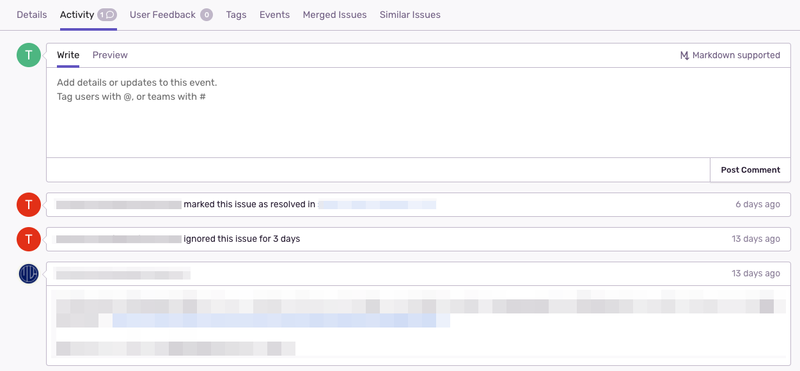
(Sentry) Activityの活用
Activityに関しては、先述の通り過去の知見 (e.g. 調査方法、対処法) の活用という課題において、有効な機能であると考えています。
Markdownの形式もサポートし、調査・対応結果のような知見をActivityにまとめるための基本的な機能を有しています。
ステータスの変更やActivityを更新したユーザーも確認できるので、Activityに記載のない機微な内容に関して直接確認することもできます。
(Sentry → Datadog) Trace idを用いたDatadogへの導線作り
エラーなどの事象調査においては、Sentryだけで完結しないケースもサポートが必要になります。
例えば、エラー情報だけではなく、メトリクス・エラーとなったHTTP request前後のログも含めて調査・確認を進める場合は、Datadogの利用を考慮すべきです。
本項目の説明の前提として、新環境ではCloud runを利用しており、Cloud runは2種類のlogが存在します。
https://cloud.google.com/run/docs/logging
- リクエストログ: Cloud Runサービス側で自動生成されたHTTP requestに関するログ
- コンテナログ: Cloud Runのserviceで稼働しているコンテナでLoggerを利用してユーザー側が出力したログ
例として、発生したエラーイベントに関連して、ある特定のHTTP reqeustに紐づく2種類のログを一気通貫で見たいケースを想定します。
上記のケースへの対応も踏まえて、X-Cloud-Trace-Context のrequest headerからHTTP Requestに紐づくTrace idを抽出して、Sentry用にcustom tagを追加しています。
https://cloud.google.com/run/docs/logging#run_manual_logging-python
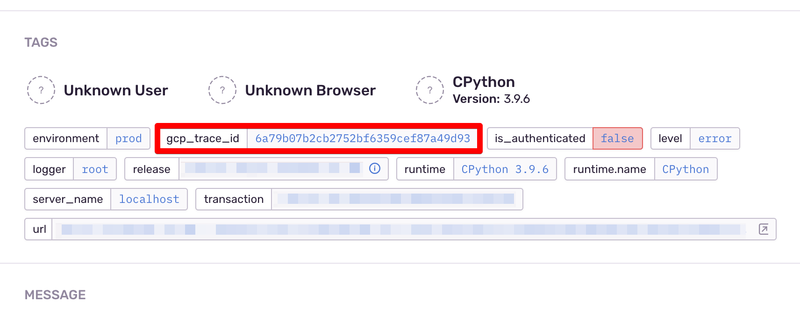
抽出されたtrace_idを用いて、最終的にDatadog側でエラー発生時のrequestに紐づく一連のログをfilterして確認できるようになります。
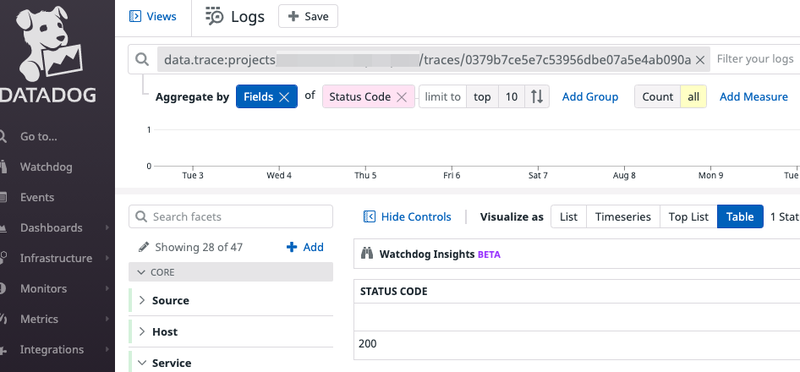
監視ツールはケースによる使い分けが前提になると思うので、ツールを横断して利用する際の導線的なものとしてTrace idを活用できると考えました。
(Datadog) Monitorを利用したRunbookの提供
各種ツールを利用していき、ある程度エラー対応の知見が溜まると、典型的なケースでの対応内容をRunbook (手順書) として整備することもできます。
https://www.pagerduty.com/resources/learn/what-is-a-runbook/
これは、個別のエラー対応の事例を踏まえて汎化させるという意味で、一種の連結化と言えるかと思います。
ただ、Runbook自体をどのように管理するのか (e.g. Datadog monitorの通知時に表示されるMessageにまとめる or Messageにはリンクを載せてRunbookはGitHubで管理する etc.) など、試行錯誤の状態が続いています。
この部分に関しては引き続き最適な方法を検討していきます。
終わりに
実際に利用しているツールや機能を交えつつ、「運用の属人化」に対する課題意識、(技術・ツール面の観点からの) 属人化へのアプローチについてまとめました。
施策は始まったばかりですが、ツールを利用して運用作業自体の負荷を軽減し、ノウハウを集約できる状態を整備できれば、少しづつ成果が見えてくるかと思います。
エラー対応などの運用作業は「知識と経験の合わせ技」という側面もあり、改善へのアプローチが難しい部分もあるかと思いますが、このブログが参考になれば幸いです。