朝寒くなってきたので、午前中は家でリモート作業することが多くなりそう・・ビザスクの検索エンジニア tanker です。
前回 (GCE での Elasticsearch サーバスペック見積もり検証 1) の続きになりますので、まだご覧になっていない方はお先にお読みになることをお勧めします。
お品書き
前回の次回予告でも書いた通り、今回の検証の準備段階~分析段階で具体的にどのようなことをやったのかを書きたいと思います。
- オリジナルの index のみで data を増やしたり、field 増やしたり index を増やしたりする方法
- 検証用の検索クエリーの抽出方法
- 負荷ツールとして vegeta を使う方法
- 監視用の agent を常駐させずにメトリックス監視をする方法
なお、 Elasticsearch は 6.7系です。
準備: 検証用の index を作る
今回、検証用に独立した環境で行ったため、DB から reindex する方法が使えず、 original の index をコピーしたりして検証用の index を作りました。
Elasticsearch には、そういう時に使える API がいくつも用意されています。
https://www.elastic.co/guide/en/elasticsearch/reference/6.8/docs.html
template を登録
reindex API 等で コピーはできても analyzer などが設定されていないため意図した挙動になりません。 検証用の index 名のパターンを決めて template を適用します。
$ curl -XPUT -H'content-type:application/json' $HOSTNAME:9200/_template/template_test -d@template_tanker.json
{"acknowledged":true}
$ curl -ISs $HOSTNAME:9200/_template/template_test
HTTP/1.1 200 OK
$ cat template_tanker.json
{
"index_patterns": ["test-*"],
"settings": {
"index": {
"number_of_replicas": "1",
"number_of_shards": "5",
"analysis": {
...
},
...
}
},
"mappings": {
"data": {
"properties": {
"search": {
"properties": {
"updated": {
"type": "date"
},
...
}
}
}
}
}
}
index 数を増やす
reindex API を使って clone します。
$ curl -XPUT $HOSTNAME:9200/test-a
$ curl -XPOST -H'content-type:application/json' $HOSTNAME:9200/_reindex -d'{"source": {"index": "original-index"},"dest": {"index": "'test-a'"}}'
doc 数を増やす
こちらも reindex API を使うのですが、 script を使って、 doc ID を異なるものを作ります。(先に、「index数を増やす」の手順で original の clone である test-a が作られている前提です)
$ curl -XPOST -H'content-type:application/json' $HOSTNAME:9200/_reindex -d@twice_doc.json
$ cat twice_doc.json
{
"source": {
"index": "original-index"
},
"dest": {
"index": "test-a"
},
"script": {
"lang": "painless",
"source": "ctx._id = '2nd-' + ctx._id"
}
}
field を増やす
Update By Query API を使います。ビザスクで使っているものが mapping 全体を 「search」というフィールド名で囲んでいるためこのような手法が使えたのだと思います。(URLの data は type 名) (先に test-a が作られている前提です)
add_field.json の search の部分を search2 に変更して、それ以外のフィールド情報は template で使ったものと同じにします。
$ curl -XPUT -H'content-type:application/json' $HOSTNAME:9200/test-a/_mapping/data/ -d@add_field.json
$ curl -XPOST -H'content-type:application/json' $HOSTNAME:9200/test-a/_update_by_query?conflicts=proceed -d@update_by_query.json
$ cat add_field.json
{
"properties": {
"search2": {
"properties": {
"updated": {
"type": "date"
},
...
}
}
}
}
$ cat update_by_query.json
{
"script":{
"source": "ctx._source.search2 = ctx._source.search"
}
}
準備: 検証用の検索クエリーの抽出方法
今回は、本番の検索クエリーを使いました。具体的には、1か月分の検索クエリーを抽出し、それをレイテンシー順に並べて 10分割し、 それぞれ 50件ずつ取って 計 500クエリー用意しました。 これは、検索の負荷の様子を可能な限り本番と合わせるためです。
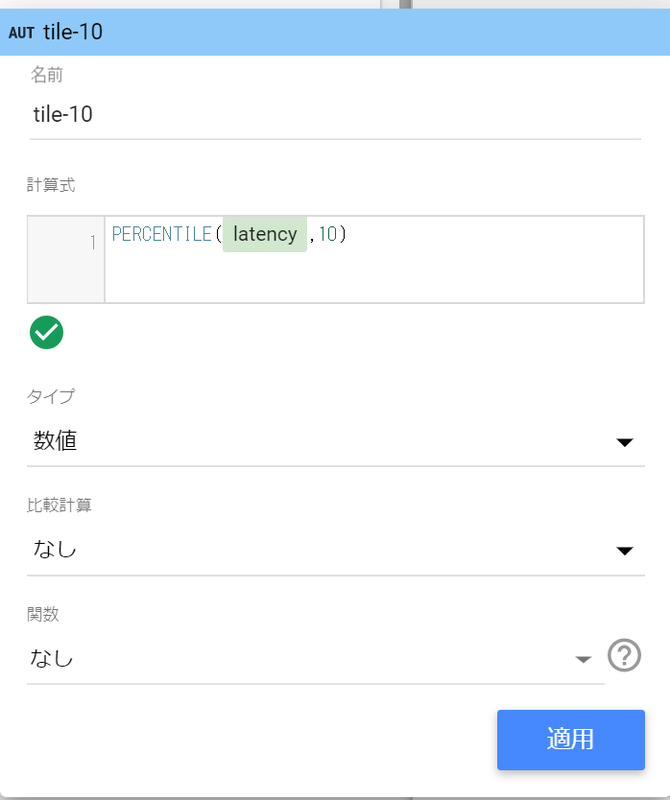
BigQuery を使って、検索クエリーのレイテンシーパーセンタイルを求めます。(elasticsearch_query_paramsは検索リクエストログに含まれるように仕込んだ文字列です)
SELECT
insertId,protoPayload.latency
FROM
`hogehoge_request_log_201911*`,
UNNEST(protoPayload.line) as l
WHERE
l.logMessage LIKE 'elasticsearch_query_params%';
BigQuery からデータポータルにエクスポートします。
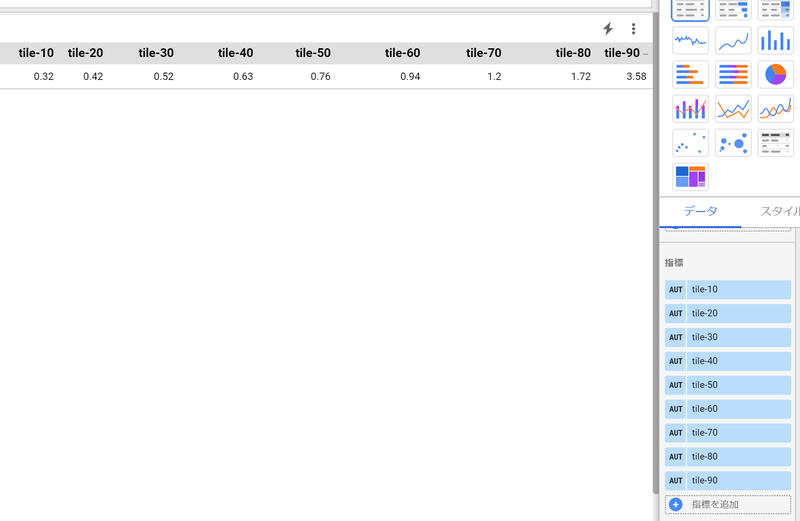
このデータをもとに BigQuery の方で、 50件ずつ取得していきます。
SELECT
l.logMessage
FROM
`hoge_request_log_201911*`,
UNNEST(protoPayload.line) as l
WHERE
l.logMessage LIKE 'elasticsearch_query_params%' AND protoPayload.latency >= [ A ] AND protoPayload.latency < [ B ]
LIMIT 50;
検証: vegeta を使って検索クエリーを投げる
https://github.com/tsenart/vegeta は Go 言語で書かれた負荷ツールです。バイナリーも用意されているので、 Go 環境を用意する必要はありません。
$ ./vegeta attack -rate=10 -duration=5s -targets=target.txt | ./vegeta report
Requests [total, rate, throughput] 50, 10.20, 5.59
Duration [total, attack, wait] 8.9412324s, 4.8998813s, 4.0413511s
Latencies [mean, 50, 95, 99, max] 4.860466258s, 5.0343798s, 6.4792325s, 6.5742004s, 6.5742004s
Bytes In [total, mean] 6850, 137.00
Bytes Out [total, mean] 864000, 17280.00
Success [ratio] 100.00%
Status Codes [code:count] 200:50
Error Set:
このような感じで、 CUI で成形された情報が表示されるので 助かりました。
今回の検証では、Letencies (レイテンシーのパーセンタイル)の部分と Success (リクエストの成功[200]率) の部分を主に見ました。
$ cat target.txt
GET http://tanker-es02/test-a/_search
content-type:application/json
@q.json
GET http://tanker-es02/test-a/_search
content-type:application/json
@q.json
上記のような ファイルを用意して、実行時に指定します。 q.json には検索クエリーが入っています。単一 URL に色々な JSON を投げる場合は、1クエリー毎にjson ファイルを分割して target.txt に列挙していく必要があります。ちなみに、リクエストされる順番は、 愚直に target.txt を上から順番に 末尾まで行ったらまた先頭に戻るという挙動でした。
監視用の agent を常駐させずにメトリックス監視をする方法
仰々しく書いてしまいましたが、かなり手作業が多いので 検証など一時的に使うとき専用の方法です。Linux のコマンドでメトリック情報を毎秒 TSV 形式で出力したものを Kibana の File Data Visualizer を使って import して グラフ表示します。
JVM Heap
$ apt-get install gawk
$ chmod 755 jstat.sh
$ ./jstat.sh test2.tsv
$ cat jstat.sh
#!/bin/bash
if [ $# -ne 1 ]; then
echo "出力ファイル名を指定してください"
exit 1
fi
PID=`sudo -u elasticsearch /usr/share/elasticsearch/jdk/bin/jps | grep Elasticsearch | cut -d' ' -f1`
if [ -n "$PID" ]; then
sudo -u elasticsearch /usr/share/elasticsearch/jdk/bin/jstat -gcutil -t $PID 1s | awk 'BEGIN{OFS="\t"}{print strftime("%Y-%m-%d %H:%M:%S"),$2,$3,$4,$5,$6,$7,$8,$9,$10,$11; fflush();}' > $1
fi
S0 S1 E O M CCS YGC YGCT FGC FGCT
2019/12/18-10:22:48 0.00 0.63 88.64 11.42 91.59 81.51 51 1.813 6 0.316
2019/12/18-10:22:49 0.00 0.63 88.64 11.42 91.59 81.51 51 1.813 6 0.316
jdk のパスは環境に合わせて修正してください。もし、CentOS で systemd を使っており jps でプロセス ID が取れない場合は /usr/lib/systemd/system/elasticsearch.service を修正してみてください
- PrivateTmp=true
+ PrivateTmp=false
DISK IOPS
$ sudo yum install sysstat # install されていない場合
$ iostat -dx 1 | awk -v RS="" 'BEGIN{OFS="\t"}{print strftime("%Y-%m-%d %H:%M:%S"),$18,$19; fflush();}' > iostat.log
CPU / Memory
$ vmstat -n -t 1 | awk 'BEGIN{OFS="\t"}{print strftime("%Y-%m-%d %H:%M:%S"),$3,$4,$5,$6,$13,$14; fflush();}'
Kibana に 読み込ませる
を読まれるとよいかと思います。awk で出力したものは、1行目が微妙なので 適宜手作業で修正されるとよいと思います。Kibana は 1行目をもとにフィールド名を決めるため。(import 時に UI 上から修正することも可能です) また、日付と認識される形式は いくつか決まっており、今回は awk で出力する際に指定しています。
一緒に働くエンジニアを募集中!
ビザスクではエンジニアを大募集中です! ビザスクに少しでも興味のあるWebエンジニアの方がいましたら、ぜひお話を聞かせてください!詳しい募集要項は下記リンクからアクセスしてください。
- エンジニア採用ページ: https://visasq.co.jp/engineer-recruitment
- 最近リニューアルしてかっこよくなったので是非ご覧ください!
- ビザスクの中の様子はこちらから >> https://square.visasq.com/