桜の花より団子な 検索チームの tanker です。
(管理画面検索の概要については 以前の投稿を参照ください) 管理画面検索にキーワードサジェスト機能を追加しようとした際に、過去の
RM (リサーチマネージャー) の検索クエリーなどから辞書データを生成しておく必要があります。ただし、現状検索ログは保管しているだけで活用できていません。その準備として (またはその他への活用を期待して)、管理画面検索の検索ログ基盤を Google Cloud Dataflow を使って構築するための調査を行ったので共有したいと思います。
Dataflow を選定した理由
- ビザスクのメインシステムが GCP 上にある
- 認証周りが IAM に集約できる
- Python でコードが書ける
- ビザスクの大半が Python コード
- BigQuery などの連携が簡単
- スケールしやすい
- MapReduce のように (極論)ログ1行毎にワーカーで分散される
- 一方で順序整合性が担保されなかったりするので注意
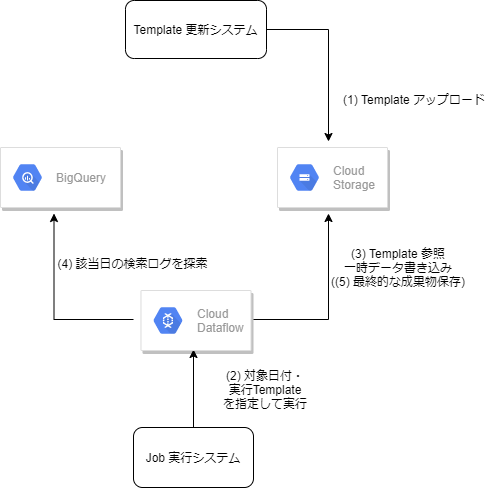
今回のゴール図
Dataflow では、大きく Template と呼ばれる処理のシナリオを記述したものを作成するフェーズ(図中の 1) と 保存された Template を 条件を指定して実行するフェーズ (図中の 2~5) に分かれます。
今回はやりませんが、最終的には (2) が scheduler の日次バッチで前日分に対して実行されることを想定しています。
1. Dataflow や Beam について知る
想定しているシステムが Dataflow で実現できそうか?については、Cloud Dataflow 超入門 を見ながらイメージを膨らませました。
2. Hello world
BigQuery 上に格納されているデータから 条件にマッチしたもののみを抽出して Cloud Storage に格納するだけの処理を行う Dataflow ジョブを作成します。
※ 超入門の事前準備の部分は省略します。IAM権限は、Dataflowアクセス制御ガイド に沿って、「 Dataflow 管理者 」を付与しています。
$ mkdir dataflow
$ cd dataflow/
$ python --version
Python 3.7.5
$ pip install apache-beam[gcp] -t . # 環境汚したくないので、ディレクトリ内にインストール
Successfully installed apache-beam-2.28.0.... # 以下略
$ touch helloworld.py
$ code . # VSCode で以下の内容を記述する
$ python helloworld.pyBigQueryのテーブルをParquet出力する(Python / Apache Beam / Dataflow)を参考にコードを書きます。
# coding: utf-8
import apache_beam as beam
from apache_beam.options.pipeline_options import GoogleCloudOptions
from apache_beam.options.pipeline_options import PipelineOptions
from apache_beam.options.pipeline_options import StandardOptions
from apache_beam.options.pipeline_options import WorkerOptions
class DataFlowOptions():
def __init__(self, project_id, job_name,
staging_location, temp_location):
self.options = PipelineOptions()
self.options.view_as(GoogleCloudOptions).project = project_id
self.options.view_as(GoogleCloudOptions).job_name = job_name
self.options.view_as(GoogleCloudOptions).staging_location = \
staging_location
self.options.view_as(GoogleCloudOptions).temp_location = temp_location
self.options.view_as(GoogleCloudOptions).region = 'asia-northeast1'
self.options.view_as(WorkerOptions).autoscaling_algorithm = \
'THROUGHPUT_BASED' # スループットに合わせて自動でスケーリング
self.options.view_as(StandardOptions).runner = 'DataflowRunner'
class DataFlowClient():
def __init__(self, project_id):
self.project_id = project_id
def output_gcs(self, job_name, gs_bucket, gs_staging, gs_temp_dir,
gs_output_file, from_date, to_date):
staging_location = 'gs://{}/{}'.format(gs_bucket, gs_staging)
temp_location = 'gs://{}/{}'.format(gs_bucket, gs_temp_dir)
output_location = 'gs://{}/{}'.format(gs_bucket, gs_output_file)
query = """\
SELECT
l.logMessage
FROM
`your_project.logs.log_*` as req_log,
UNNEST(protoPayload.line) as l
WHERE
_TABLE_SUFFIX BETWEEN '{}' AND '{}'
AND l.logMessage LIKE '%search_request_params%'
""".format(from_date, to_date)
# オプションの設定
options = DataFlowOptions(self.project_id, job_name, staging_location,
temp_location)
p = beam.Pipeline(options=options.options)
(
p
| 'Input: ReadTable' >> beam.io.gcp.bigquery.ReadFromBigQuery(
query=query,
use_standard_sql=True)
| 'Output: Export to GCS' >> beam.io.WriteToText(
output_location,
shard_name_template="")
)
p.run()
if __name__ == '__main__':
projectid = 'your_project'
job_name = 'tanker-helloworld'
gcs_bucket = 'tanker-search-log' # 先ほど作った bucket 名
staging_dir = 'staging' # 自動で作られる
temp_dir = 'temp' # 同上
output_file = 'results5' # 同上
date_from = '20210226'
date_to = '20210226'
dfc = DataFlowClient(projectid)
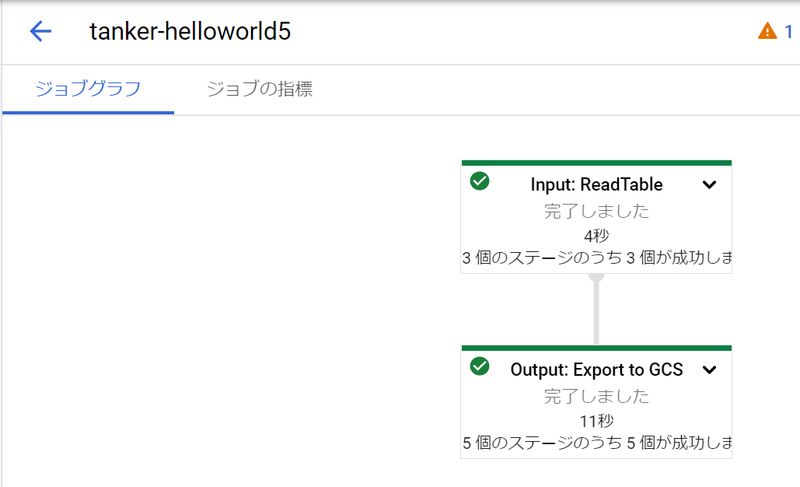
dfc.output_gcs(job_name, gcs_bucket, staging_dir, temp_dir, output_file, date_from, date_to)実行に成功すると、 GCP の Dataflow のジョブ一覧に表示されます。 Cloud Storage の方にも output ファイルが出力されていることが確認できました。
余談ですが、最初は上記の超入門を参考にコードを書いたのですが、実行するとブラウザが立ち上がり、権限を求めるダイアログが表示され、許可を選択しても「このアプリはブロックされます」という警告がでて実行できませんでした。 (何が原因だったのは突き詰めてはいないです) このページに貼ったコードだとそもそも権限を求められたりはしませんでした。

3. Template として出力
ここまでは、コンソールで直接実行していましたが、実運用では Template を登録して、それを他の Python のコードから実行します。
以下のコードを追加して、再度実行すると ジョブが走らない代わりに、指定された Cloud Storage の場所に ファイルが生成されます。
+ self.options.view_as(GoogleCloudOptions).template_location = \
+ template_location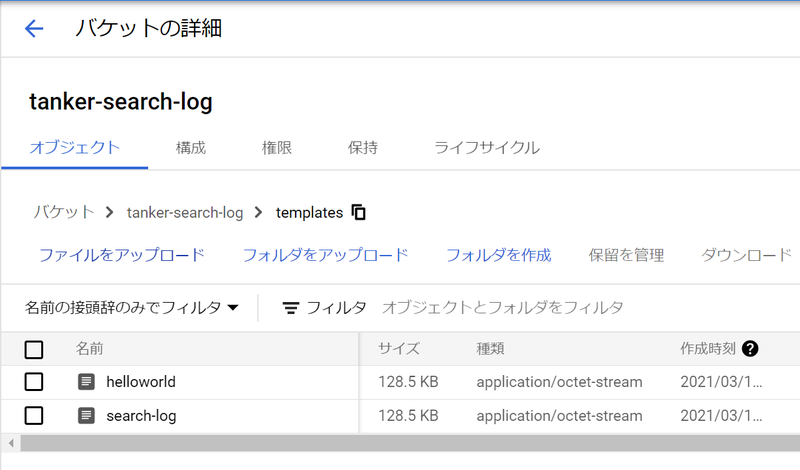
4. 呼び出すプログラムを作成
登録された Template を使って Dataflow のジョブを実行する方法は 公式ドキュメント にあるようにいくつも用意されています。今回は、
「Google API クライアント ライブラリの使用」 の方法で行います。
$ pip install google-api-python-client -t .
$ touch request.py
$ code . # VSCode で以下のコードを貼り付け
$ python request.py# coding: utf-8
from googleapiclient.discovery import build
gcs_bucket = 'tanker-search-log'
template_file = 'templates/search-log'
project = 'your-project'
job = 'tanker-search-log'
template = 'gs://{}/{}'.format(gcs_bucket, template_file)
dataflow = build('dataflow', 'v1b3')
request = dataflow.projects().templates().launch(
projectId=project,
gcsPath=template,
body={
'jobName': job,
# 'parameters': parameters,
}
)
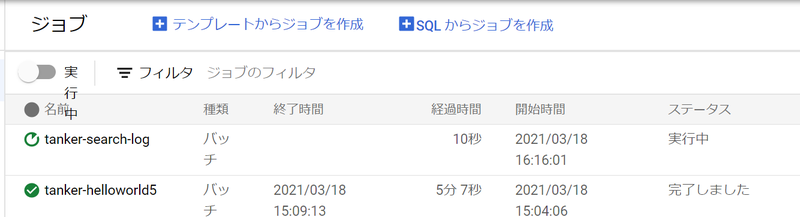
response = request.execute()実行すると、Dataflow のジョブ一覧で実行されているのを確認できます。
5. 実行時の引数
実行日の前日分のデータを読み込むようにしたいので、BigQuery で動的に日付を変えれるようにします。ちなみに、Template 経由で引数を渡す場合は add_value_provider_argumentReadFromBigQueryの場合は、 公式ドキュメントにある通り ValueProvider 型が利用可能な table か query でのみ使用できます。なので、引数には、日付ではなく クエリー全体を入れる必要があります。 (クエリーがシンプルなら table パラメータを使って DataflowのWriteToBigQueryでRuntimeValueProviderで渡した日付のパーティション分割テーブルを作る のように lambda 関数を使うことで、引数に日付だけ渡す方法もあるようです)
+ class WithArgsOptions(PipelineOptions):
+ @classmethod
+ def _add_argparse_args(cls, parser):
+ parser.add_value_provider_argument('--query', type=str)
+
+
=======
p = beam.Pipeline(options=options.options)
+ pp_options = options.options.view_as(WithArgsOptions)
# pipeline 本体
(
p
| 'Input: ReadTable' >> beam.io.gcp.bigquery.ReadFromBigQuery(
- query=query,
+ query=pp_options.query,
use_standard_sql=True)request.py の方も修正します
+ query = """\
+ SELECT
+ l.logMessage
+ FROM
+ `{}.log_{}` as req_log,
+ UNNEST(protoPayload.line) as l
+ WHERE
+ l.logMessage LIKE '%search_request_params%'
+ """.format(table, datetime.datetime.strftime(yesterday, '%Y%m%d'))
+ parameters = {
+ 'query': query,
+ }6. 外部ライブラリ
外部ライブラリを使う場合は、Cloud DataflowのテンプレートにPythonの外部パッケージを利用するを参考にされるとよいと思います。 (今回は省略)
7. (駆け足で) ステップの拡充
ETL といいつつ、ただ出力しているだけだったので、整形を行う処理を追加しました。
具体的には、
- BigQuery の返り値の timestamp 型を iso 形式の文字列に変換
- 検索クエリーを パースする処理 ( pyparsing を使ってやりました。別の記事で書くかもしれません)
- 一連の検索行動をグルーピングするために sesssion_id を付与
の3つです。
# pipeline 本体
(
p
| 'Input: ReadTable' >> beam.io.gcp.bigquery.ReadFromBigQuery(
query=pp_options.query,
use_standard_sql=True)
| 'Append: timestamp_iso' >> beam.Map(append_ts_formatted)
| 'Append: parsed_query.query' >> beam.ParDo(QueryParserDoFn('query'))
| 'Append: parsed_query.company_name' >> beam.ParDo(
QueryParserDoFn('company_name'))
| 'convert to tuple with user_id' >> beam.Map(convert_tuple)
| 'group by user_id' >> beam.GroupByKey()
| 'order by timestamp' >> beam.Map(order_by_timestamp)
| 'Append: session_id' >> beam.Map(append_session_id)
| 'flat tuple' >> beam.FlatMap(flat_tuple)
| 'Output: Export to GCS' >> beam.io.WriteToText(
output_location,
shard_name_template="")
)少し詰まったところとして ParDoの処理で 返り値が期待通りのものが返ってこなかったのですが、返したい結果を List で囲ってあげると 解決しました。
return [table_row]結び
あくまでも今回は検証段階でしたが、おおよそ Dataflow を使った運用ができそうだという手ごたえは得られました。整形部分を強化したり、出力を BigQuery にしたり 今後もう少し手を加えていきたいと思います。